Mastering Missing Data: A Guide to Robust Preprocessing
The Silent Model Killer
Missing data is one of the most common yet pervasive challenges in machine learning. Whether caused by sensor failures, user omissions, or data corruption, gaps in your dataset can lead to biased models and poor performance. Ignoring them is rarely an option, but filling them incorrectly can be even worse.
In this guide, we explore the best strategies for handling missing values and how AIMU simplifies this critical preprocessing step.
Strategies for Handling Missing Values
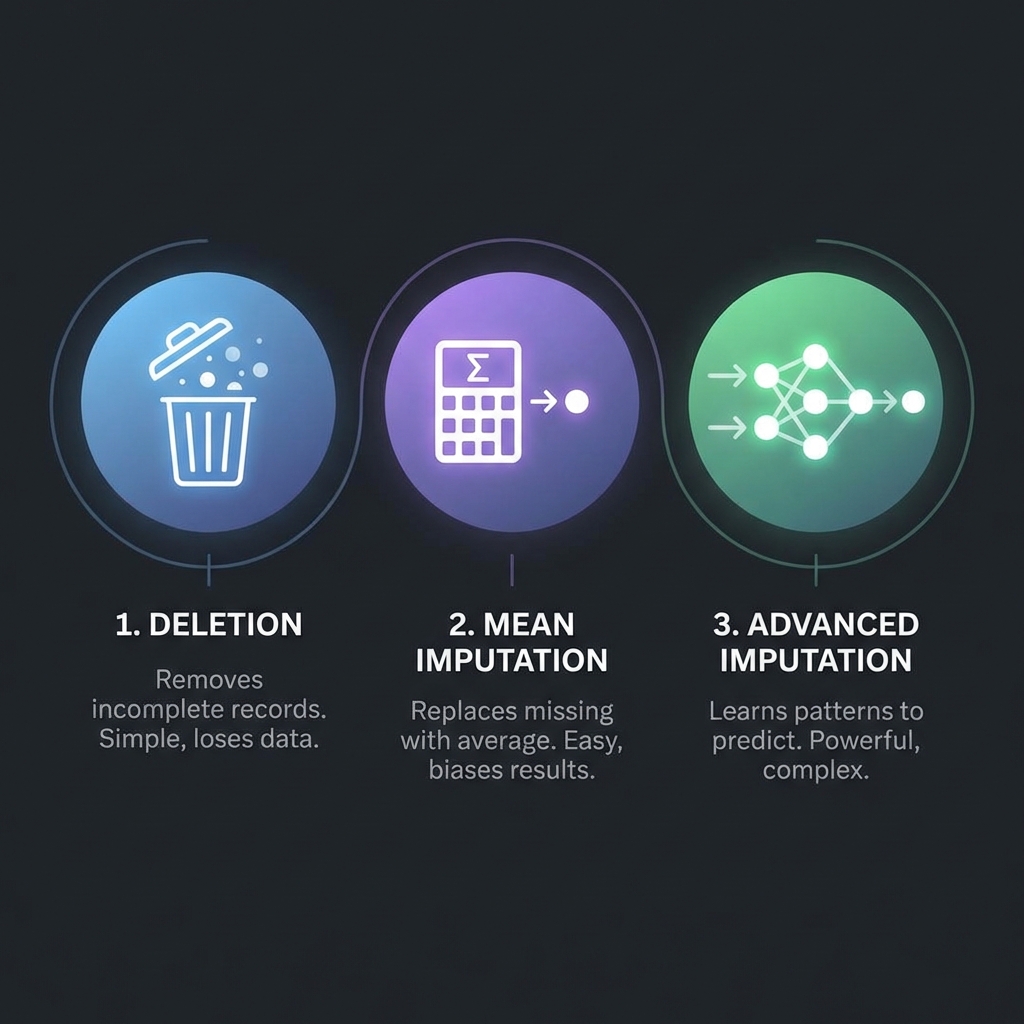
The three pillars of missing data handling: Deletion, Statistical Imputation, and Advanced Imputation.
1. Deletion (The "Nuclear" Option)
The simplest approach is to remove rows or columns containing missing values. While effective for massive datasets with negligible missingness, it carries significant risks:
- Loss of Information: You discard potentially valuable data points.
- Bias Introduction: If data is not missing at random (MNAR), deletion introduces selection bias.
2. Statistical Imputation
A more balanced approach involves filling gaps with statistical estimates:
- Mean/Median Imputation: Replaces missing values with the average or median of the column. Good for continuous data but can distort variance.
- Mode Imputation: Uses the most frequent value, ideal for categorical data.
- Forward/Backward Fill: Useful for time-series data, propagating the last known value forward.
3. Advanced Imputation
For complex datasets, machine learning models can predict missing values based on correlations with other features. Techniques like K-Nearest Neighbors (KNN) or deep learning autoencoders offer superior accuracy at the cost of computational complexity.
Handling Missing Data in AIMU
AIMU creates a seamless workflow for identifying and treating missing values without writing a single line of code. Our dedicated preprocessing interface puts powerful imputation methods at your fingertips.
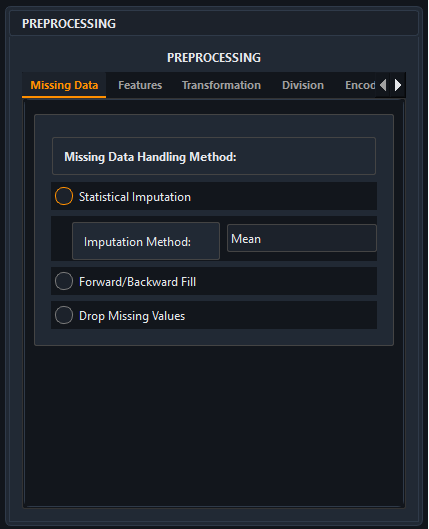
The AIMU Preprocessing Dashboard allows you to toggle between Statistical Imputation, Forward Fill, and Drop methods instantly.
With AIMU, you can:
- Visualize Missingness: Instantly see which features are incomplete.
- Select Strategies: Choose between Mean, Median, Mode, or Forward/Backward fill with a click.
- Preview Results: See how your choice affects the data distribution in real-time.
Conclusion
Data quality is the foundation of AI success. By robustly handling missing values, you ensure your models learn from the whole picture, not just the fragments. Whether you choose simple imputation or advanced techniques, consistency is key.